Hello 👋
This is my code blog, where I write about projects I’ve been working on and guides I wish I’d had.
This is my code blog, where I write about projects I’ve been working on and guides I wish I’d had.
I’m sorry for the lack of project updates 🙇 I have been working on a lot of OSS work so this has taken a back seat. However, I have added a lot to the project since my last update . It’s nearing completion.
The usefulness of linters should not be understated, they act as a lightweight form of PR review.
In fact, the Google SRE guide suggests that “nitpick” comments should be left to linters.
Linters help prevent obvious bugs and serve as guardians of code quality.
I’ve been on quite a journey with testing, When I first started they were the part of the codebase constantly breaking and causing endless regeneration. Luckily, that was some time ago and my views have matured, mostly through being burned by not building tests and seeing the difficulty of replicating a bug.
Muzz social is the largest muslim social network in the world, we allow for users to post, comment and share their experiences with each other.
At the start of the year we added a simple but effective impressions system. We used the page which the user was requesting to be counted as an impression, we then stored the results of this inside ElastiCache (Valkey). Every time the feed was requested we would then exclude the posts unless the comment count had changed by a significant amount. This change created a very positive change for our users seeing a 22% increase in feed requests over the two months after we rolled out the feature. However there was an inherent issue with this which was that just because the whole page was requested it does not mean it had been seen. So quickly after this was released we started work on its successor named mobile impressions. The system was to be near real time, it also had to be durable as we did not want to drop events as this could cause inconvenience to the users. This was no mean feat as we handle around 150,000 events a minute all of this would need to be processed and handled as quickly as possible. Muzz social uses an event driven architecture meaning when certain actions happen it creates events which can be tapped into this allows us to extend existing functionality in a scalable and controllable way.
Muzz Social is the world’s leading Muslim-focused social network. We allow people to share and connect with Muslims around the world.
Muzz Social sends push notifications for posts to users who haven’t been on the platform for 48 hours. These notifications are generated by selecting the most engaging and relevant posts, helping to re-engage users and surface content they might have missed. This feature has proven effective in delivering posts that matter to users.
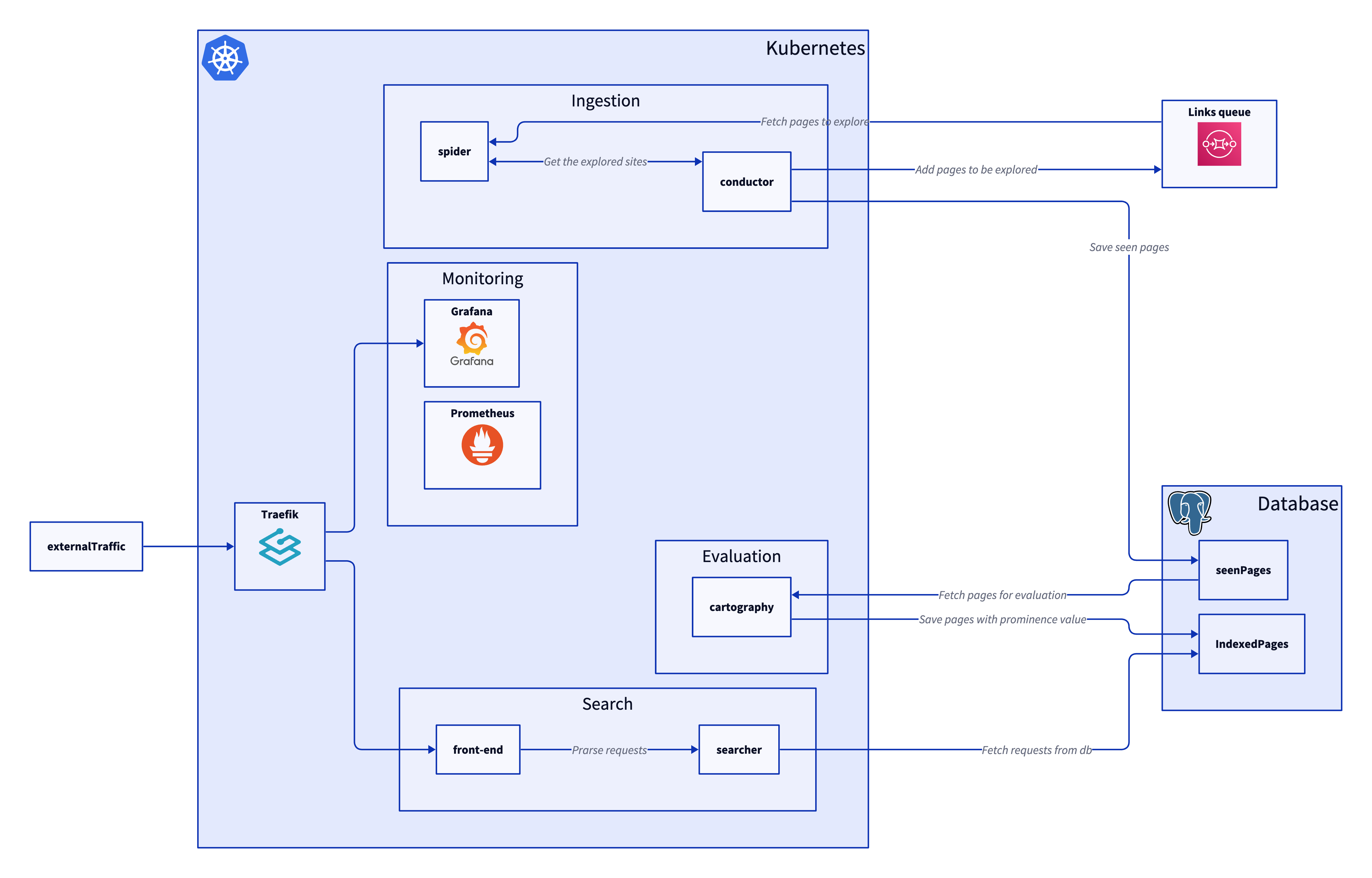
One of the key parts of the design of my search engine is the ability for the spiders to send the pages which they have explored to a central point. Additionally, a more conventional design might use a push/pull system, so the conductor polls each spider in turn and requests the pages which it has seen using pagination. This has several problems.
As I mentioned in my last Building a Search engine , I’ve been busy building my search engine lately, and it’s been a lot of fun diving deep into Kubernetes and learning how to set everything up from scratch.
I was re-reading “I am feeling lucky” and this inspired me, so I have decided to create a search engine. This is a very ambitious project; however, it will teach me a lot about building a micro service with Kubernetes all from scratch.
My plan is to refactor the spider to use a relational database. I am learning towards each spider having its own SQLite db. Then create a service which can go to the spiders and get their current crawl and add them to a central DB. This will create a single graph of all the visited notes.
At first glance, this question might seem trivial. However, the process behind a browser loading a webpage is a complex marvel that we take for granted every day—handling millions of requests and intricate routing to reach servers like Google’s. Let’s take a journey into this process.
We’ll break it down into two main steps: first, discovering the site’s address, and second, retrieving data from that site. For the sake of brevity, some details will be simplified.
As 2024 draws to an end, it’s time for me to reflect on the year’s achievements and challenges.
Overall, 2024 was a year of growth, and I’m really happy with the improvement in the quality of my work. Here’s what I learned and worked on: