Search Engine Update 1
As, I mentioned in my last post . I’ve been busy building my search engine lately, and it’s been a lot of fun diving deep into Kubernetes and learning how to set everything up from scratch.
Overview of the System
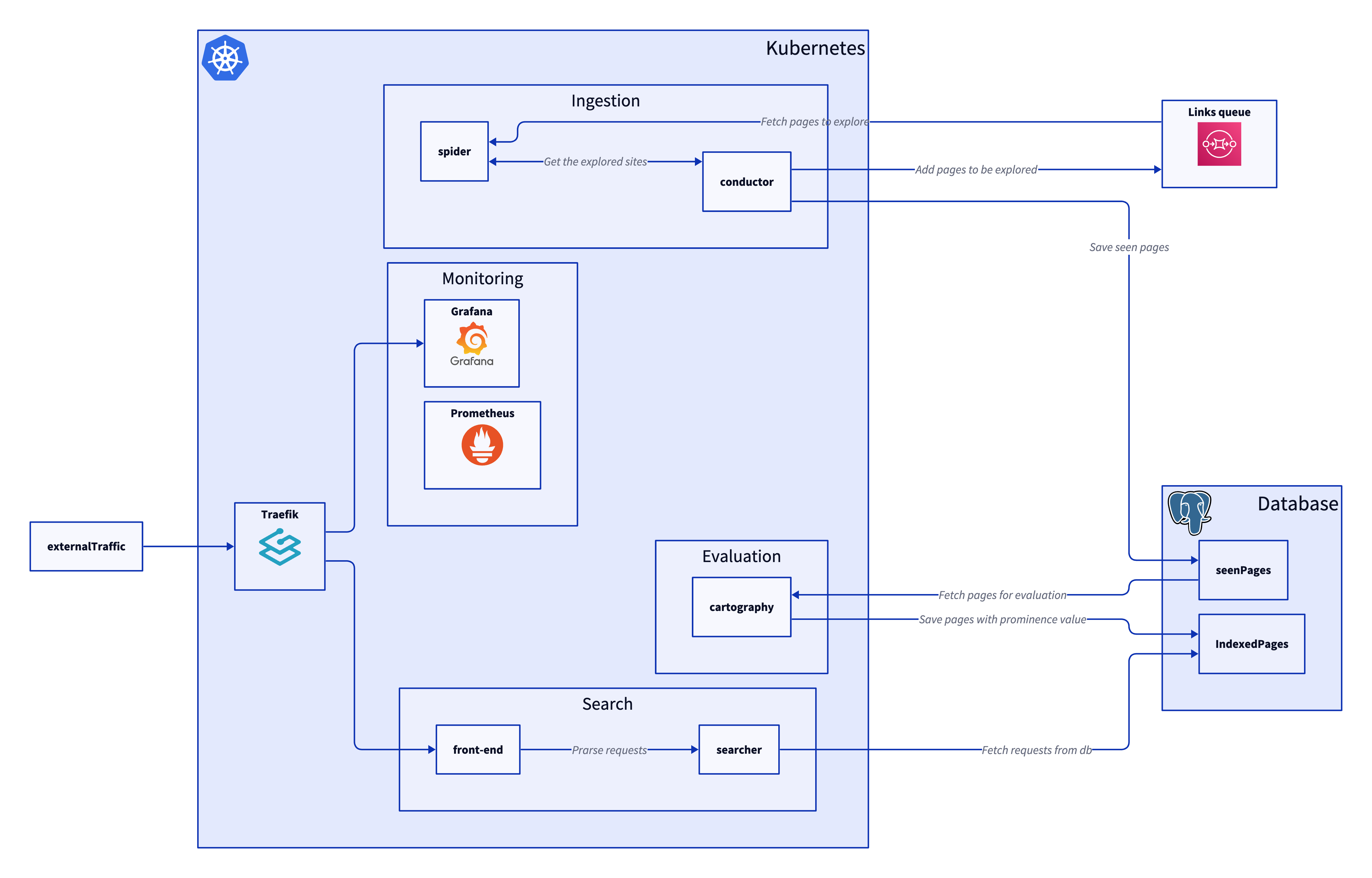
Spider
- Fetches websites and stores them in a local database.
- Uses bi-directional gRPC to stream data to the Conductor.
- Retrieves URLs to explore from SQS.
Conductor
- Receives crawled pages from the Spider.
- Updates the main table of seen pages.
- Queues new pages to explore in SQS.
Cartographer
- Pulls pages from the seen pages table.
- Builds an adjacency list and assigns a prominence score to each page.
- Stores the results in the index table.
Searcher
- Uses the index table to return the most relevant pages for a search query.
What’s Been Done
Spider
- Migrated to a relational database (SQLite).
- Now exposes a gRPC endpoint consumed by the Conductor.
Observability
- Set up Grafana and Prometheus for system monitoring.
- Integrated OpenTelemetry for distributed tracing.
RPC (Spider ↔ Conductor)
- Implemented gRPC streaming to allow real-time, bidirectional communication.
Kubernetes
- Cluster configured to pull container images from AWS ECR.
Trade-Offs
Database
- Using Postgres for the main system and SQLite for the Spider.
- SQLite is lightweight, requires no additional services, and is ideal for isolated Spider instances.
- Postgres offers scalability and flexibility for future features like word embeddings and graph search.
Spider ↔ Conductor
- The Conductor is the bottleneck in this architecture.
- To mitigate this, I implemented bidirectional streaming over gRPC. The Conductor can send back “can’t keep up” messages when overwhelmed.
- Streaming enables incremental, real-time submission of crawled pages.
AWS SQS
- Chosen due to familiarity and reliability.
- Enables horizontal scaling by allowing multiple Spiders to fetch tasks independently.
Prometheus
- Opted for a
/metricsendpoint over a sidecar to reduce RAM usage and simplify deployment.
- Opted for a
Future
At the next update, I plan to have:
- Public Grafana dashboard
- Implement
- Conductor
- Cartographer