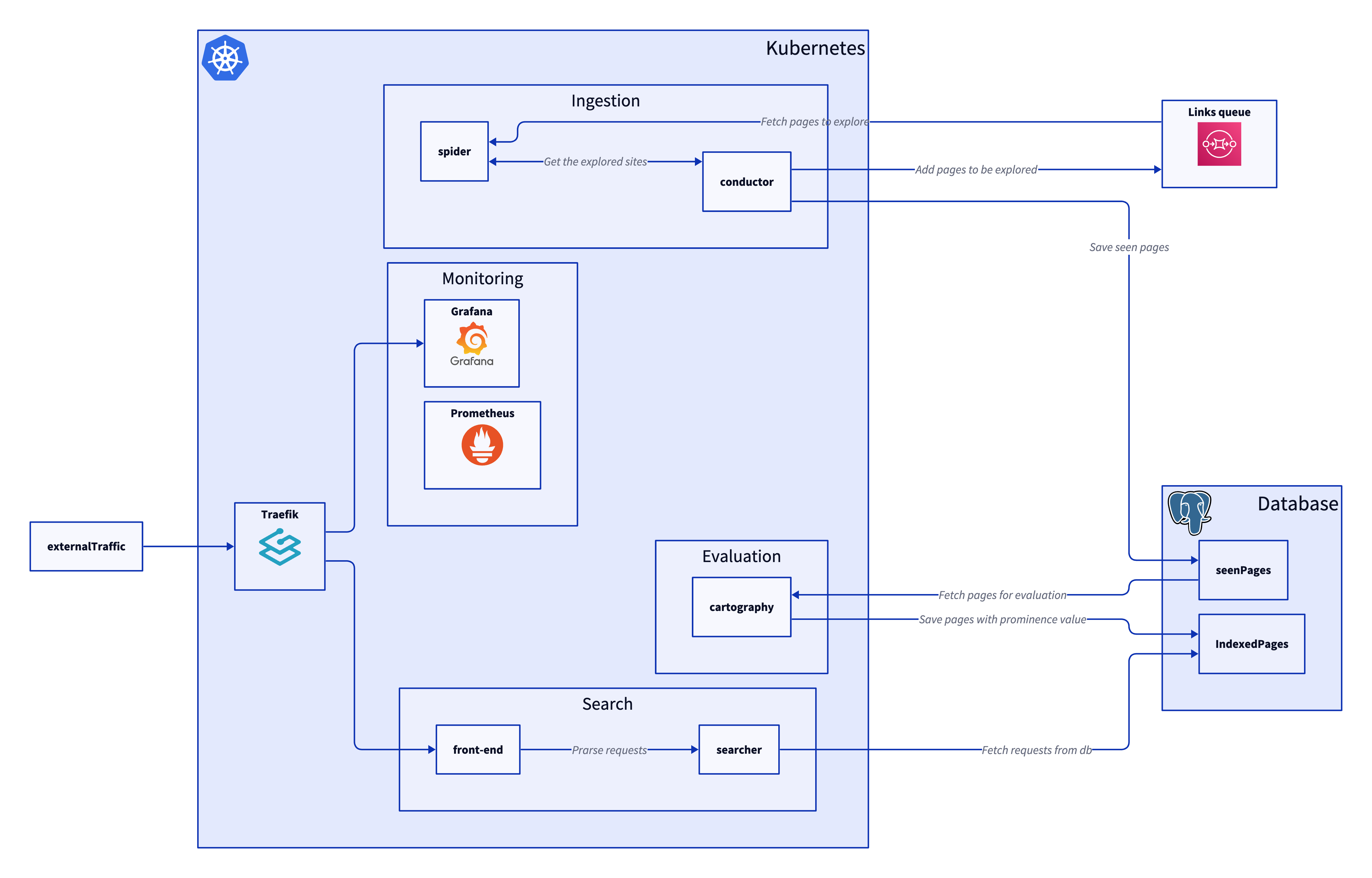
Over the past few weeks I have been making a webcralwer. I wanted to do it as way to get better at Go with useful for learnings for Graph databases as well as being fun. The project made use of cloud native items such as AWS SQS, DynamoDB and optionally Neptune which could be swapped out for Neo4j.
Over the past few weeks I have been making a webcralwer. I wanted to do it as way to get better at Go with useful for learnings for Graph databases as well as being fun. The project made use of cloud native items such as AWS SQS, DynamoDB and optionally Neptune which could be swapped out for Neo4j.
A webcrawler or web spider is a program which visits a website, and fetches all of the links on that site and then visits them. This is how sites like Google/Bing/DuckDuckGo get the pages to populate when searching.