Search Engine Update 2
Search Engine Project Update
I’m sorry for the lack of project updates 🙇 I have been working on a lot of OSS work so this has taken a back seat. However, I have added a lot to the project since my last update . It’s nearing completion.
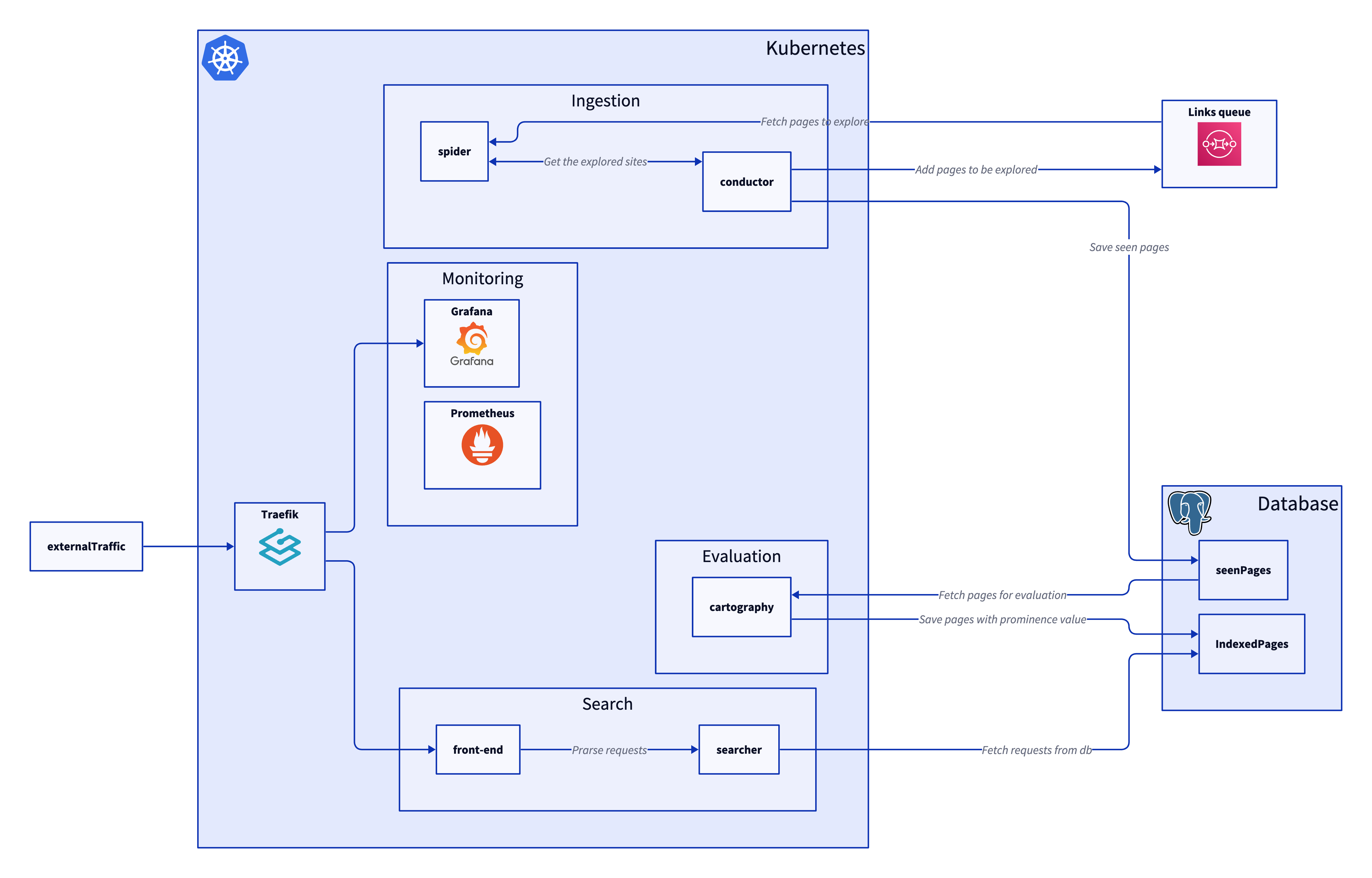
 Over the past few weeks I have been making a webcralwer. I wanted to do it as way to get better at Go with useful for learnings for Graph databases as well as being fun. The project made use of cloud native items such as AWS SQS, DynamoDB and optionally Neptune which could be swapped out for Neo4j.
Over the past few weeks I have been making a webcralwer. I wanted to do it as way to get better at Go with useful for learnings for Graph databases as well as being fun. The project made use of cloud native items such as AWS SQS, DynamoDB and optionally Neptune which could be swapped out for Neo4j.